当项目在数据库层面出现瓶颈时,添加一个缓存系统就成了一件不得不考虑的事,而设计一个完善的缓存系统,通常需要解决以下几个问题:缓存穿透、缓存雪崩和缓存击穿。
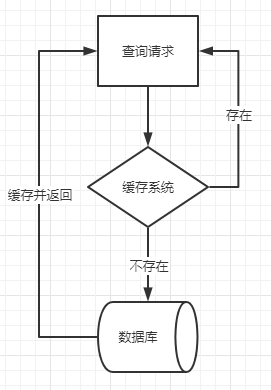
缓存调用过程
缓存系统的调用过程是这样的:当我们请求一条数据时,先去缓存中查询,如果存在就直接返回,如果不存在就去数据库查询,然后进行缓存并返回,可以有效的减轻数据库的压力并提升响应速度。
缓存穿透
什么是缓存穿透
正常情况下,查询的数据都是存在的,但是当请求查询一个一定不存在的数据时,缓存和数据库中都不存在这条记录,那么请求就会直接落到数据库上,这种直接查询数据库的现象称为缓存穿透。如果有恶意用户以不存在的key去查询数据,产生大量请求,从而导致所有的查询都落到数据库,会使数据库压力过大而影响正常服务甚至宕机。
解决方案
缓存空值或者默认值
这种方式简单粗暴,即使查询返回空结果,仍然对该查询进行缓存,并对其设置一个较短的过期时间,避免产生了真实的数据而无法查出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 伪代码
String get(String key) {
// 从缓存获取数据
String data = Redis.get(key);
if (null != data) {
return data;
}
// 从数据库获取数据
data = DB.get(key);
if (null == data) {
// 如果结果为空,那么将结果赋值为空值
data = Data.Empty;
// 将缓存过期时间设置为较短的值
expired = sort;
}
// 缓存查询结果
Redis.add(key, data, expired);
return data;
}
缓存空值虽然简单,但是弊病还是很明显的,如果有恶意攻击短时间请求大量不重复的key,那么查询依旧会落到数据库上,同时缓存系统也会缓存下大量不存在的数据,占用缓存空间,这是需要考虑到的。
布隆过滤器
布隆过滤器(BloomFilter)是一个数组形式且足够大的bitmap,通过多次哈希将数据映射到bitmap中。布隆过滤器可以快速检索一个数据是否包含在它所表示的集合中,它有一个特点,不存在的数据则一定不存在,表示存在的数据则大概率存在(这和布隆过滤器的误判率有关)。当布隆过滤器应用于防止缓存穿透时,我们可以事先将缓存的数据加载到布隆过滤器中,并将布隆过滤器置于缓存系统之前。得益于布隆过滤器的特点,当请求查询一个不存在的数据时,布隆过滤器可以将其直接过滤掉,而不会落到缓存系统和数据库上。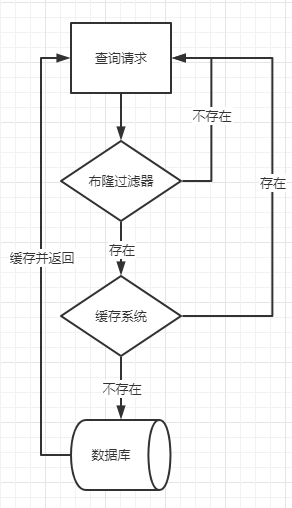
布隆过滤器的解决之道足够优秀,但是其依旧是存在不足之处的:一是因为哈希冲突,布隆过滤器存在一定的误判率,即表示存在的结果不一定真实存在,数据库查询结果也可能为空;二是布隆过滤器没有删除操作,对于数据库删除的数据,不能达到很好的过滤效果。
缓存雪崩
什么是缓存雪崩
对于设置了过期时间的数据,在同一时间大规模的失效,或者缓存服务器宕机不能提供服务,导致查询直接落到数据库的现象称为缓存雪崩。缓存雪崩导致大量的请求转到数据库,在面对大量的请求时会给数据库带来巨大的压力。
解决方案
随机失效时间
通常在数据预热阶段,会对数据进行缓存设置,将缓存数据的过期时间在原来的基础上增加一个随时值,可以避免在某个时间出现大规模的缓存失效的情况,这样即使出现失效,也不会导致数据库瞬时负载过大而影响性能的情况。
永不过期
(1)在设置缓存数据时不设置过期时间,物理意义上的不过期;
(2)为缓存数据的过期时间进行动态设置,避免冷门数据一直占有空间。在设置缓存时,可以将过期时间存在key对应的value里,如果取出来时发现即将过期,则后台新开一个线程对该缓存数据进行更新,但是这种方案存在脏读的可能,在更新缓存期间,部分线程读取到的可能是旧数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 伪代码
String get(String key) {
Data data = Redis.get(key);
String value = data.getValue();
long timeout = data.getTimeout();
if (timeout <= System.currentTimeMillis()) {
// 后台异步更新
ThreadPool.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
// 使用SETNX抢占互斥锁,设置互斥锁过期时间,避免删除失败导致锁无法释放
if (Redis.setnx(keyMutex, "1", 3 * 60)) {
Data data = DB.get(key);
Redis.set(key, data, expired);
// 删除互斥锁
Redis.delete(keyMutex);
}
}
});
}
return value;
}配置缓存服务器集群
为避免缓存服务器宕机影响服务,可以采用服务器集群,保证缓存服务的高可用。比如Redis,可以使用主从、哨兵或者Cluster模式来避免全盘崩溃的情况,发生宕机也可以快速恢复重启并提供服务。
缓存击穿
什么是缓存击穿
在高并发的环境中,热点数据会被大量请求,而当热点数据过期失效时,这些请求会从数据库查询数据并回设到缓存中,大量的请求落到数据库时会压力骤增,可能会压垮数据库。与缓存雪崩不同的是,缓存击穿针对的是某些访问频次极高的热点数据失效,是一个“点”,缓存雪崩是因为大面积的缓存失效,是一个“面”。
解决方案
设置数据永不过期
此方案和缓存雪崩的永不过期方案基本类似,使缓存数据不失效即可。
限流/降级
对高并发的接口进行限流,常用的策略有:滑动窗格、令牌桶、漏桶等,未通过限流的请求,走服务降级,只要请求的数量不会把数据库压垮,那就不会影响系统的总体稳定,这是牺牲部分用户的体验换取的服务安全。
互斥锁
用互斥锁来限制查询数据库的线程数量,避免大量的请求落到数据库,单机环境可以使用
ReentrantLock,分布式可以使用SETNX加锁,获取到锁的线程去查询数据并更新缓存,其他线程则等待重试。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 伪代码
String get(String key) {
String value = Redis.get(key);
if (value == null) {
String keyMutex = "mutex:" + key;
// 使用SETNX抢占互斥锁,单机环境可以使用其他独占锁,设置互斥锁过期时间,避免删除失败导致无法释放
if (Redis.setnx(keyMutex, "1", 3 * 60)) {
value = DB.get(key);
Redis.set(key, value, expired);
Redis.delete(keyMutex);
} else {
// 未获取到锁的线程50毫秒后重试
Thread.sleep(50L);
// 递归调用
return get(key);
}
}
return value;
}
参考: